
Qualcomm model deployment
Qualcomm provides the qai_hub_models Python library. It enables developers to easily perform model conversion and quantization, and export the as BIN files that can be directly loaded by Qualcomm NPU. The library also supports model inference and validation using Qualcomm's online virtual devices.
Preparations
- Install qai_hub_models on device.
pip3 install qai_hub_models
- Configure API Token.
Please register an account on Qualcomm® AI Hub and log in to obtain the user API Token.
export PATH=~/.local/bin/:$PATH
qai-hub configure --api_token <API_TOKEN>
Model core information
The models supported by qai_hub_madels include 4 types of Computer vision, Multinodal, Audio, and Generation. Please refer to the table below for details.
Computer vision
| Model | README |
|---|---|
| Qualcomm model download center | Github repository address |
| Image classification | |
| Beit | qai_hub_models.models.beit |
| ConvNext-Base | qai_hub_models.models.convnext_base |
| ConvNext-Tiny | qai_hub_models.models.convnext_tiny |
| DLA-102-X | qai_hub_models.models.dla102x |
| DenseNet-121 | qai_hub_models.models.densenet121 |
| EfficientFormer | qai_hub_models.models.efficientformer |
| EfficientNet-B0 | qai_hub_models.models.efficientnet_b0 |
| EfficientNet-B4 | qai_hub_models.models.efficientnet_b4 |
| EfficientNet-V2-s | qai_hub_models.models.efficientnet_v2_s |
| EfficientViT-b2-cls | qai_hub_models.models.efficientvit_b2_cls |
| EfficientViT-l2-cls | qai_hub_models.models.efficientvit_l2_cls |
| GoogLeNet | qai_hub_models.models.googlenet |
| Inception-v3 | qai_hub_models.models.inception_v3 |
| LeViT | qai_hub_models.models.levit |
| MNASNet05 | qai_hub_models.models.mnasnet05 |
| Mobile-VIT | qai_hub_models.models.mobile_vit |
| MobileNet-v2 | qai_hub_models.models.mobilenet_v2 |
| MobileNet-v3-Large | qai_hub_models.models.mobilenet_v3_large |
| MobileNet-v3-Small | qai_hub_models.models.mobilenet_v3_small |
| NASNet | qai_hub_models.models.nasnet |
| RegNet | qai_hub_models.models.regnet |
| ResNeXt101 | qai_hub_models.models.resnext101 |
| ResNeXt50 | qai_hub_models.models.resnext50 |
| ResNet101 | qai_hub_models.models.resnet101 |
| ResNet18 | qai_hub_models.models.resnet18 |
| ResNet50 | qai_hub_models.models.resnet50 |
| Sequencer2D | qai_hub_models.models.sequencer2d |
| Shufflenet-v2 | qai_hub_models.models.shufflenet_v2 |
| SqueezeNet-1.1 | qai_hub_models.models.squeezenet1_1 |
| Swin-Base | qai_hub_models.models.swin_base |
| Swin-Small | qai_hub_models.models.swin_small |
| Swin-Tiny | qai_hub_models.models.swin_tiny |
| VIT | qai_hub_models.models.vit |
| WideResNet50 | qai_hub_models.models.wideresnet50 |
| Image editing | |
| AOT-GAN | qai_hub_models.models.aotgan |
| LaMa-Dilated | qai_hub_models.models.lama_dilated |
| Image generation | |
| Simple-Bev | qai_hub_models.models.simple_bev_cam |
| Super resolution | |
| ESRGAN | qai_hub_models.models.esrgan |
| QuickSRNetLarge | qai_hub_models.models.quicksrnetlarge |
| QuickSRNetMedium | qai_hub_models.models.quicksrnetmedium |
| QuickSRNetSmall | qai_hub_models.models.quicksrnetsmall |
| Real-ESRGAN-General-x4v3 | qai_hub_models.models.real_esrgan_general_x4v3 |
| Real-ESRGAN-x4plus | qai_hub_models.models.real_esrgan_x4plus |
| SESR-M5 | qai_hub_models.models.sesr_m5 |
| XLSR | qai_hub_models.models.xlsr |
| Semantic segmentation | |
| BGNet | qai_hub_models.models.bgnet |
| BiseNet | qai_hub_models.models.bisenet |
| DDRNet23-Slim | qai_hub_models.models.ddrnet23_slim |
| DeepLabV3-Plus-MobileNet | qai_hub_models.models.deeplabv3_plus_mobilenet |
| DeepLabV3-ResNet50 | qai_hub_models.models.deeplabv3_resnet50 |
| DeepLabXception | qai_hub_models.models.deeplab_xception |
| EfficientViT-l2-seg | qai_hub_models.models.efficientvit_l2_seg |
| FCN-ResNet50 | qai_hub_models.models.fcn_resnet50 |
| FFNet-122NS-LowRes | qai_hub_models.models.ffnet_122ns_lowres |
| FFNet-40S | qai_hub_models.models.ffnet_40s |
| FFNet-54S | qai_hub_models.models.ffnet_54s |
| FFNet-78S | qai_hub_models.models.ffnet_78s |
| FFNet-78S-LowRes | qai_hub_models.models.ffnet_78s_lowres |
| FastSam-S | qai_hub_models.models.fastsam_s |
| FastSam-X | qai_hub_models.models.fastsam_x |
| HRNet-W48-OCR | qai_hub_models.models.hrnet_w48_ocr |
| Mask2Former | qai_hub_models.models.mask2former |
| MediaPipe-Selfie-Segmentation | qai_hub_models.models.mediapipe_selfie |
| MobileSam | qai_hub_models.models.mobilesam |
| PidNet | qai_hub_models.models.pidnet |
| SINet | qai_hub_models.models.sinet |
| SalsaNext | qai_hub_models.models.salsanext |
| Segformer-Base | qai_hub_models.models.segformer_base |
| Segment-Anything-Model-2 | qai_hub_models.models.sam2 |
| Unet-Segmentation | qai_hub_models.models.unet_segmentation |
| YOLOv11-Segmentation | qai_hub_models.models.yolov11_seg |
| YOLOv8-Segmentation | qai_hub_models.models.yolov8_seg |
| Video | Classification |
| ResNet-2Plus1D | qai_hub_models.models.resnet_2plus1d |
| ResNet-3D | qai_hub_models.models.resnet_3d |
| ResNet-Mixed-Convolution | qai_hub_models.models.resnet_mixed |
| Video-MAE | qai_hub_models.models.video_mae |
| Video generation | |
| First-Order-Motion-Model | qai_hub_models.models.fomm |
| Object detection | |
| 3D-Deep-BOX | qai_hub_models.models.deepbox |
| Conditional-DETR-ResNet50 | qai_hub_models.models.conditional_detr_resnet50 |
| DETR-ResNet101 | qai_hub_models.models.detr_resnet101 |
| DETR-ResNet101-DC5 | qai_hub_models.models.detr_resnet101_dc5 |
| DETR-ResNet50 | qai_hub_models.models.detr_resnet50 |
| DETR-ResNet50-DC5 | qai_hub_models.models.detr_resnet50_dc5 |
| Facial-Attribute-Detection | qai_hub_models.models.face_attrib_net |
| Lightweight-Face-Detection | qai_hub_models.models.face_det_lite |
| MediaPipe-Face-Detection | qai_hub_models.models.mediapipe_face |
| MediaPipe-Hand-Detection | qai_hub_models.models.mediapipe_hand |
| PPE-Detection | qai_hub_models.models.gear_guard_net |
| Person-Foot-Detection | qai_hub_models.models.foot_track_net |
| RF-DETR | qai_hub_models.models.rf_detr |
| RTMDet | qai_hub_models.models.rtmdet |
| YOLOv10-Detection | qai_hub_models.models.yolov10_det |
| YOLOv11-Detection | qai_hub_models.models.yolov11_det |
| YOLOv8-Detection | qai_hub_models.models.yolov8_det |
| Yolo-X | qai_hub_models.models.yolox |
| Yolo-v3 | qai_hub_models.models.yolov3 |
| Yolo-v5 | qai_hub_models.models.yolov5 |
| Yolo-v6 | qai_hub_models.models.yolov6 |
| Yolo-v7 | qai_hub_models.models.yolov7 |
| Pose estimation | |
| Facial-Landmark-Detection | qai_hub_models.models.facemap_3dmm |
| HRNetPose | qai_hub_models.models.hrnet_pose |
| LiteHRNet | qai_hub_models.models.litehrnet |
| MediaPipe-Pose-Estimation | qai_hub_models.models.mediapipe_pose |
| Movenet | qai_hub_models.models.movenet |
| Posenet-Mobilenet | qai_hub_models.models.posenet_mobilenet |
| RTMPose-Body2d | qai_hub_models.models.rtmpose_body2d |
| Depth estimation | |
| Depth-Anything | qai_hub_models.models.depth_anything |
| Depth-Anything-V2 | qai_hub_models.models.depth_anything_v2 |
| Midas-V2 | qai_hub_models.models.midas |
Multimodal
| Model | README |
|---|---|
| EasyOCR | qai_hub_models.models.easyocr |
| Nomic-Embed-Text | qai_hub_models.models.nomic_embed_text |
| OpenAI-Clip | qai_hub_models.models.openai_clip |
| TrOCR | qai_hub_models.models.trocr |
Audio
| Model | README |
|---|---|
| Speech recognition | |
| HuggingFace-WavLM-Base-Plus | qai_hub_models.models.huggingface_wavlm_base_plus |
| Whisper-Base | qai_hub_models.models.whisper_base |
| Whisper-Large-V3-Turbo | qai_hub_models.models.whisper_large_v3_turbo |
| Whisper-Small | qai_hub_models.models.whisper_small |
| Whisper-Tiny | qai_hub_models.models.whisper_tiny |
| Audio classification | |
| YamNet | qai_hub_models.models.yamnet |
Generation
| Model | README |
|---|---|
| Image generation | |
| ControlNet-Canny | qai_hub_models.models.controlnet_canny |
| Stable-Diffusion-v1.5 | qai_hub_models.models.stable_diffusion_v1_5 |
| Stable-Diffusion-v2.1 | qai_hub_models.models.stable_diffusion_v2_1 |
| Text generation | |
| ALLaM-7B | qai_hub_models.models.allam_7b |
| Baichuan2-7B | qai_hub_models.models.baichuan2_7b |
| Falcon3-7B-Instruct | qai_hub_models.models.falcon_v3_7b_instruct |
| IBM-Granite-v3.1-8B-Instruct | qai_hub_models.models.ibm_granite_v3_1_8b_instruct |
| IndusQ-1.1B | qai_hub_models.models.indus_1b |
| JAIS-6p7b-Chat | qai_hub_models.models.jais_6p7b_chat |
| Llama-SEA-LION-v3.5-8B-R | qai_hub_models.models.llama_v3_1_sea_lion_3_5_8b_r |
| Llama-v2-7B-Chat | qai_hub_models.models.llama_v2_7b_chat |
| Llama-v3-8B-Instruct | qai_hub_models.models.llama_v3_8b_instruct |
| Llama-v3.1-8B-Instruct | qai_hub_models.models.llama_v3_1_8b_instruct |
| Llama-v3.2-1B-Instruct | qai_hub_models.models.llama_v3_2_1b_instruct |
| Llama-v3.2-3B-Instruct | qai_hub_models.models.llama_v3_2_3b_instruct |
| Llama3-TAIDE-LX-8B-Chat-Alpha1 | qai_hub_models.models.llama_v3_taide_8b_chat |
| Ministral-3B | qai_hub_models.models.ministral_3b |
| Mistral-3B | qai_hub_models.models.mistral_3b |
| Mistral-7B-Instruct-v0.3 | qai_hub_models.models.mistral_7b_instruct_v0_3 |
| PLaMo-1B | qai_hub_models.models.plamo_1b |
| Phi-3.5-Mini-Instruct | qai_hub_models.models.phi_3_5_mini_instruct |
| Qwen2-7B-Instruct | qai_hub_models.models.qwen2_7b_instruct |
| Qwen2.5-7B-Instruct | qai_hub_models.models.qwen2_5_7b_instruct |
Model compilation
The details of compilation take Yolov7 as an example,please refer to the relevant model README file for details:
export PRODUCT_CHIP=qualcomm-qcs6490
pip3 install "qai-hub-models[yolov7]"
python3 -m qai_hub_models.models.yolov7.export --chipset ${PRODUCT_CHIP} --target-runtime qnn_context_binary --quantize w8a8
- --chipset: Specifies the target chip to run on
- --target: Specifies the target runtime
- --quantize: Specifies the quantization method
The above command generates a mode-id and a file named yolov7.qnn_context_binary, which is the runtime model file for the target chip.
Run demo
python3 -m qai_hub_models.models.yolov7.demo --quantize w8a8
- If you want to run demo on cloud devices, you need to add the hub-model-id parameter
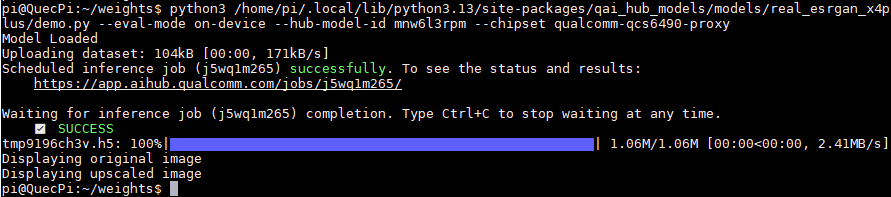
Use NPU of local device for inference validation
Please refer NPU development guide.
Q&A
How to use models to develop app ?
Qualcomm provides the ai-engine-direct-helper SDK, which includes Python and C++ interfaces for developing apps that can load models and perform inference. For details, please refer to ai-engine-direct-helper.